Quantization in Deep Learning
Quantization
Quantization is a part of that process that convert a continuous data can be infinitely small or large to discrete numbers within a set variety, say numbers 0, 1, 2, .., 255 which are generally used in virtual image files. In Deep Learning, quantization normally refers to converting from floating-factor (with a dynamic range of the order of 1x10 -³⁸ to 1x10 ³⁸) to constant factor integer (e.g- 8-bit integer between 0 and 255). Some records might
be misplaced in quantization but researches show that with hints in training, the loss in accuracy is manageable.

Why Quantization?
There are two main explanations for this. Deep Neural Network includes many parameters which are called weights, for example, the famous VGG network has over 100 million parameters!! In many scenarios, the bottleneck of strolling deep neural community is in moving the weights and information between foremost memory and compute cores. Therefore, as opposed to GPU
which have one massive shared pool of memory, present-day AI chips have a variety of local memories across the compute cores to minimize the statistics switch latency. Now, by using the usage of 8-bit integer in place of 32-bit, we right away speed up the memory switch by 4x! This also brings other benefits that accompany smaller file size i.e. much less memory storage, faster download time etc.
How to Quantize?

There are 2 methods of Quantizing the model,
1. Post Training Quantization
a) Weight Quantization
The very simple post-training quantization is quantizing most effective weights from FP to 8-bit precision. This option is to be had with TFLite converter. At inference, weights are converted from 8-bits of precision to floating-point and computed using floating-point kernels. This conversion is carried out once and cached to lessen latency.
import tensorflow as tf
converter =tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
tflite_quant_model = converter.convert()b) Integer Quantization
In this method, we can reduce the size of the model by quantizing the weights to integer-only accelerators compatible model devices(such as 8-bit microcontrollers & Coral Edge TPU).
import tensorflow as tf
converter =tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
def representative_dataset_gen():
for _ in range(num_calibration_steps):
# Get sample input data as a numpy array in a method
yield [input]
converter.representative_dataset = representative_dataset_gen
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.int8 # or tf.uint8
converter.inference_output_type = tf.int8 # or tf.uint8
tflite_quant_model = converter.convert()c) Float 16 Quantization
The IEEE standard for 16-bit floating-point numbers. We can reduce the size of a floating-point model by quantizing the weights to float16. This technique reduces the model size by half with minimal loss of accuracy as compared to other techniques. This technique model will “dequantize” the values of the weight to float32 when running on the CPU.
import tensorflow as tf
converter =tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.lite.constants.FLOAT16]
tflite_quant_model = converter.convert()In all these cases, taking a model trained for FP32 and directly quantizing it to FP16, INT8 or pruning the weights, without any re-training, can result in a relatively low loss of accuracy (which may or may not be acceptable, depending on the use case).
2. Quantization-Aware Training
There could be an accuracy loss in a post-training model quantization and to avoid this and if you don’t want to compromise the model accuracy do quantization aware training. To overcome post-training quantization technique drawbacks we have quantization aware model training. This technique ensures that the forward pass matches precision for both training and inference. In this technique Tensorflow created flow, wherein the process of constructing the graph you can insert fake nodes in each layer, to simulate the effect of quantization in the forward and backward passes and to learn ranges in the training process, for each layer separately.
Enough Theory!!! Let’s do some coding…
We will implement a simple TF model using FashionMNIST Dataset using Quantization-Aware Training. The code has been implemented using Google Colab and in the following steps, I have just provided code snippets. For full execution of code, you can find in my Github.
1. Install Tensorflow, Tensorflow Model Optimization Library
!pip install -q tensorflow-model-optimizationfrom __future__ import absolute_import, division, print_function, unicode_literalstry:
%tensorflow_version 2.x
except Exception:
passimport tensorflow as tf
import os
import datetime
import tensorflow_datasets as tfds
%load_ext tensorboard
2. Importing & Downloading the Datasets
import tensorflow_datasets as tfdsdatasets, info = tfds.load(name='fashion_mnist', with_info=True, as_supervised=True, try_gcs=True, split=['train','test'])
3. Defining Some Utility Functions
# Function to Scale Images
def scale(image, label):
image = tf.cast(image, tf.float32)
image /= 255.0
return image, label# Split Function to Split the Dataset
def get_dataset(batch_size=64):
train_dataset_scaled = train.map(scale).shuffle(60000).batch(batch_size)
test_dataset_scaled = test.map(scale).batch(batch_size)
val_dataset_scaled = val.map(scale).batch(batch_size)
return train_dataset_scaled, test_dataset_scaled, val_dataset_scaled
4. Defining the Neural Network Model
def create_model():
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(64, 2,
padding='same', activation='relu',
input_shape=(28,28,1)))
model.add(tf.keras.layers.MaxPooling2D())
model.add(tf.keras.layers.Dropout(0.2)) model.add(tf.keras.layers.Conv2D(128, 2,
padding='same', activation='relu'))
model.add(tf.keras.layers.MaxPooling2D())
model.add(tf.keras.layers.Dropout(0.2)) model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(256))
model.add(tf.keras.layers.Activation('relu'))
model.add(tf.keras.layers.Dropout(0.2))
model.add(tf.keras.layers.Dense(10))
model.add(tf.keras.layers.Activation('softmax'))
return model5. Create the Model with Quantization-Aware Training
import tensorflow_model_optimization as tfmot
model = create_model()
quantize_model = tfmot.quantization.keras.quantize_model
q_aware_model = quantize_model(model)
q_aware_model.compile(optimizer = 'adam',
loss = 'sparse_categorical_crossentropy',
metrics = ['accuracy'])
q_aware_model.summary()6. Train the Model with QAT
train_dataset, test_dataset, val_dataset = get_dataset()
train_dataset.cache()
val_dataset.cache()
q_aware_model.fit(train_dataset,
validation_data=val_dataset,
epochs=5,
callbacks=tensorboard_callback)model.save('/tmp/fashion.hdf5')7. Evaluating & Converting the QAT Model
# Evaluating the Model
q_aware_model.evaluate(test_dataset,verbose=0)#Converting the Model using TFlite Converter
converter = tf.lite.TFLiteConverter.from_keras_model(q_aware_model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
quantized_tflite_model = converter.convert()
quantized_model_size = len(quantized_tflite_model) / 1024
print('Quantized Model Size is %dKBs,' % quantized_model_size)Note: The size of the Quantized Model was found 1.6MB which is very less compared to the original model without quantization which was around 6MB.

8. Allocating Tensors & assigning the Input and Output Details
# Allocating Tensors
interpreter = tf.lite.Interpreter(
model_content = quantized_tflite_model)
interpreter.allocate_tensors()# Assigning Input & Output Index Details to Tensors
input_tensor_index = interpreter.get_input_details()[0]["index"]
output_index = interpreter.tensor(
interpreter.get_output_details()[0]["index"])9. Inference the trained Model & Calculate the Accuracy
prediction_output = []
accurate_count = 0for test_image in test.map(scale):
test_image_p = np.expand_dims(test_image[0],axis=0).astype(np.float32)
interpreter.set_tensor(input_tensor_index,test_image_p)interpreter.invoke()
out = np.argmax(output_index()[0])
prediction_output.append(out)if out == test_image[1].numpy():
accurate_count += 1accuracy = accurate_count/len(prediction_output_with_quant)
print(accuracy)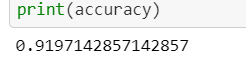
The accuracy of the Quantization-Aware Training model was found to be around 92% which is pretty similar to the original trained model without Quantization.
Conclusion
Quantization-Aware Training enables TensorFlow users to push the boundaries of efficient execution in their TensorFlow Lite-powered products and built Deep Learning application with flexible and limited memory.
The source code for this post is available on my Github.